There is no denying that artificial intelligence (AI) and machine learning technologies will shape our future. Advanced AI systems can solve the most complex business problems and create significant economic benefits for organizations. But coupling such systems with poor interpretability – also referred to as explainability – can create a recipe for disaster.
End users often have no insight into how complex AI systems work, so they are commonly viewed as black boxes. They take information and parameters as inputs, perform calculations on them in an unknown fashion, and generate predictions, recommendations, and classifications that do not always make sense to end users. The black box phenomenon can lead to issues such as unrealistic expectations for AI capabilities, poorly informed decision making, or a lack of overall trust in AI systems. These issues can jeopardize adoption across an organization and potentially cause AI implementations to fail altogether. A recent survey by IDC shows that most global organizations report some failures among their AI projects – a quarter of them report up to a 50 percent failure rate – citing as contributing factors such things as the black box phenomenon and interpretability challenges.
Despite these failures, many organizations continue to rely on AI to drive business decisions in the belief that it can exceed human capabilities. Examples include predicting asset and equipment failure in advance, optimizing supply chains and inventory, and detecting fraudulent activity. Organizations place big bets on AI to help solve business problems. What executives don’t realize is that it can adversely affect their business and end users when AI systems are not interpretable.
In this article, we outline the issues that can be addressed through implementing interpretable AI, the challenges to AI interpretability, and how the C3 AI® Platform supports AI interpretability.
Issues Interpretable AI Can Help Address
Interpretability provides the reasoning behind AI-generated predictions or recommendations to allow users to discern whether AI is “right for the right reasons.” Under this umbrella, interpretability provides benefits and reduces the risk of failure caused by the black box phenomenon on three fronts:
- Interpretability sheds light on the inner workings of black-box AI systems.
- Interpretability augments the predictions and recommendations already provided, spelling out additional insights.
- Interpretability helps identify potential issues with how the AI system was designed.
Here are some issues and key questions interpretable AI can help address:
Is your system learning the correct objective?
Interpretability is critical to ensure that AI systems are being asked to address the correct business objectives. If an AI system has poorly defined objectives, it will learn the wrong criteria, leading to unwanted outcomes and decisions. In one case, researchers applied AI to simulate a mechanism that would help decelerate fighter jets as they landed on an aircraft carrier. The AI system counterintuitively exploited the fact that maximizing the aircraft’s landing force – essentially crashing it into the carrier’s deck – would lead to an overflow and flip the speed instantly to zero, thus perfectly solving for the deceleration problem. But this only optimized for stopping the aircraft as quickly as possible while disregarding aircraft safety altogether, that clearly was meant to be a critical component of the broader objective function. Using interpretability, researchers could uncover the system’s inner workings, identify the fact that it was using the wrong objective function, and ultimately correct this problem.
Is your system trustworthy?
AI interpretability is key to developing user trust and is an integral part of change management across organizations. To develop trust in AI systems, users expect the systems to establish logical relationships between the input data and the resulting predictions. Interpretability is paramount in presenting and describing the relationships and associations between the input data and model output. Interpretable models showcase where predictive power comes from, allowing subject matter experts to determine whether that association is logically correct according to their human knowledge and experience. In one example, researchers exploring intelligible models for health care developed a model to predict pneumonia risk across a group of patients. Through interpretability, researchers identified that the AI model counterintuitively correlated having asthma with a lower risk of dying from pneumonia. Upon investigation, researchers found that patients with asthma tended to receive treatment earlier, hence lowering the risk of severe pneumonia. The AI system did not know about this interrelation. Researchers improved the model by adding additional features, subsequently demonstrating that a positive correlation exists between the level of treatment a patient receives and the lower risk of death caused by pneumonia. This AI system was untrustworthy until interpretability surfaced illogical discrepancies between the input data and model predictions, ultimately helping to fix it.
Does your system bring new insights?
Intelligible models performing beyond human capabilities can identify previously unforeseen patterns, motivating user adoption of AI. This was seen when AlphaGo beat top world players in a Go tournament. AlphaGo showcased what some described as beautiful and creative moves that Go players now are trying out as new strategies. Interpretability helps explain how such strategies or knowledge came to be, leading to fresh takes and improved capabilities for existing solutions.
Is your system ethical?
AI interpretability is an essential part of ethical AI, ensuring auditability and traceability of outcomes. Auditing model decisions allows assessment of liability and avoids legal or ethical problems that can have a huge impact on people’s lives. For example, in January 2020, the Detroit Police Department deployed a facial recognition system to identify a thief. A suspect was arrested and held for 30 hours based solely on the system’s recommendation. Charges were dropped after later comparisons between the security camera footage used and the suspect made it clear it was a false positive. If the police had been told that the identification was based only on a skin color match, the improper arrest may not have occurred. Incidents such as this will lead to needed strict ethical guidelines for AI systems, as already is being seen in the EU’s recent GDPR legislation, that requires any decision-making system to provide citizens with an explanation.
Researchers have proposed some high-level criteria for successfully integrating interpretability:
- The interpretable AI system needs to showcase what factors led to the outcomes – in other words, what data led to the prediction or recommendation.
- The interpretable AI system must permit ongoing effective control through interactive machine learning such as adding new training examples or correcting erroneous labels.
Challenges to AI Interpretability
The first challenge comes from potential conflicts between predictive and descriptive accuracy within AI-enabled solutions. Improving descriptive accuracy – interpretability – can come at the expense of predictive accuracy and, therefore, model performance.
Simple AI systems that use linear regression or tree-based models are more interpretable and understandable than their more complicated, deep learning counterparts, but simpler systems tend to provide worse predictive accuracy. This often leads to a trade-off in AI system design. But both interpretability and predictive accuracy can be achieved using model-based and post-hoc approaches.
The model-based approach improves descriptive accuracy by:
Favoring simpler models
- The C3 AI Readiness application helps improve the mission capability and readiness of military aircraft, such as helicopters. In one deployment of C3 AI Readiness, the application predicts when specific parts of the aircraft are at risk of failure – hence require maintenance – using gradient-boosted trees. For model training, we leverage data from maintenance logs and onboard sensors. By using a tree-based model – with high interpretability – maintainers now have more targeted information to troubleshoot aircraft and prioritize maintenance.
- In another case, we configured the C3 AI Predictive Maintenance application to reduce downtime in a drug manufacturing plant by predicting failure of clean-in-place (CIP) systems. These complicated pieces of equipment show little consistency over time, making it hard to model normal behavior. In this example, the application predicts the risk of failure after each cycle level using linear models. For model training, we construct sensor-based features; instead of using raw sensor values, we measure the relative deviation from the expected set points. Thanks to model interpretability, technicians can quickly check specific problematic parts to reduce the risk of overall machine failure.
Favoring features that rely on domain-specific and business-driven rules
- In the C3 AI Readiness example mentioned earlier, the critical step was finding the right representation of the input data. Working with 1,800 features from disparate sensor and maintenance systems, the team determined that crafted features – some as simple as time-since-last-maintenance or average turbine speed – drove model performance while algorithm hyperparameter optimization provided only incremental gains.
- Within the C3 AI Inventory Optimization application, supply chain customers can designate the optimal time and quantity buffer to be used for future procurement of certain SKUs within specific facilities. Because the application employs a simulation-based optimization approach, it is heavily dependent on domain knowledge and the physical dynamics of a supply chain. In order to maintain the optimization’s robustness while still providing sufficient insights to end users, the different uncertainty sources are perturbated, causing some variation in the output. This analysis of the sensitivity caused by the perturbations directly helps to derive the importance of each uncertainty factor.
The post-hoc approach explains predictions and recommendations through generating feature contributions. This is typically accomplished using third-party libraries that either A) apply a surrogate model to approximate the predictions of the underlying model, or B) directly extract contributions from the model structure itself (for example, decision paths in tree-based methods or model parameters in linear regression algorithms). We describe some of these frameworks in the final section of this post.
A second challenge of interpretable AI systems is that they need to build trust at two levels: For the model itself, known as global interpretability, and for each individual prediction, known as local interpretability. The former prevents biased models, while the latter guarantees actionable and sensical predictions. Data scientists can use these considerations to evaluate their AI systems in accordance with the needs of end users.
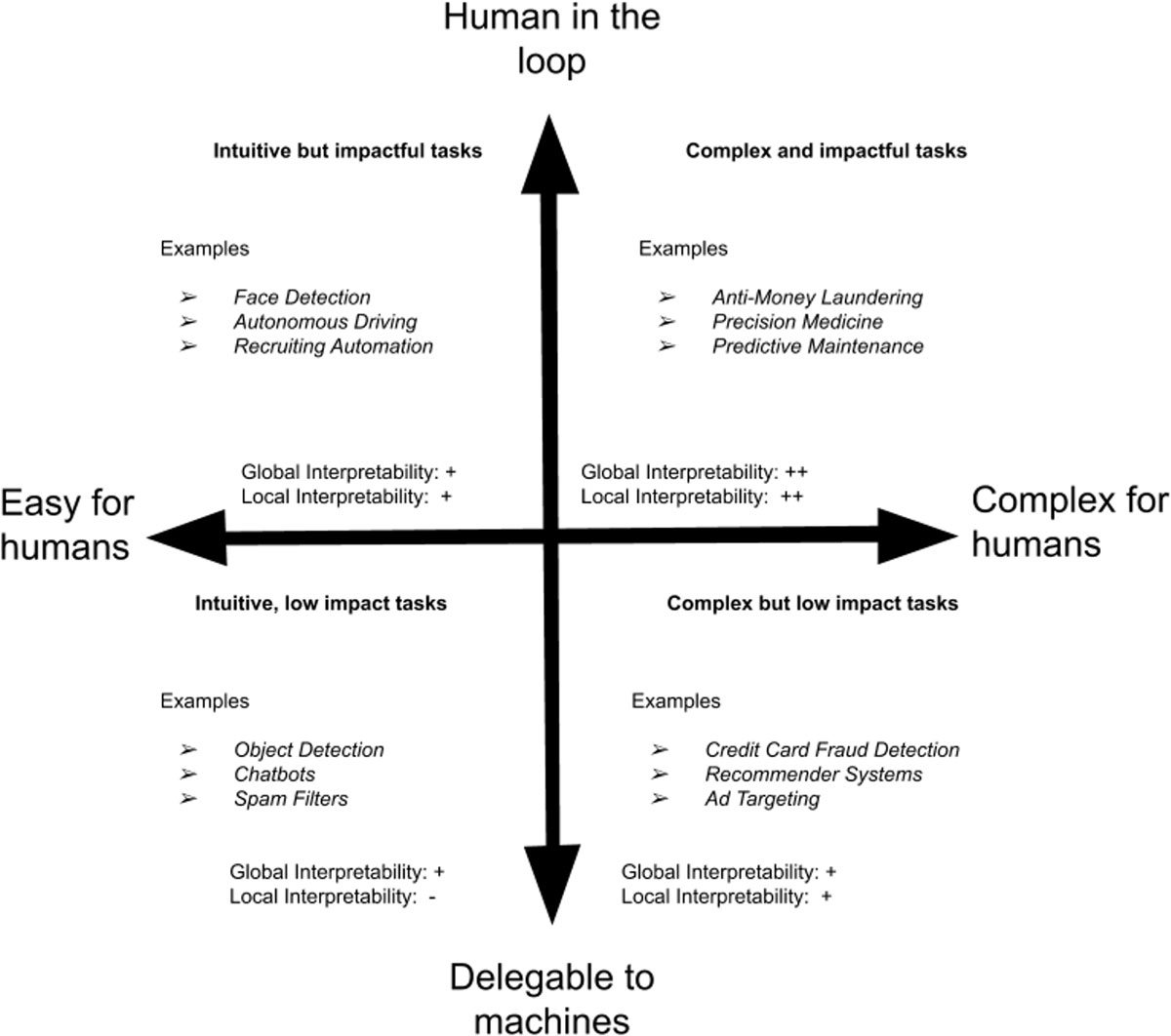
This figure illustrates when global and local interpretability are most needed as the human perception of problem complexity and the trust needed in the system vary. Global interpretability always plays an important role because AI developers need to ensure that the model is learning the right objective and is unbiased. Local interpretability is critical when problems are hard to solve, and when humans need to be in the loop to make high-stakes decisions. This is the case in anti-money-laundering applications, where large amounts of money are involved, or in precision medicine, where people’s lives are at stake. Each use case has its own unique needs and requires thorough examination to see what works best.
Interpretability on the C3 AI Platform
The C3 AI Platform leverages some of the widely used and most impactful post-hoc interpretability frameworks during development and production stages of AI systems:
- TreeInterpreter
- ELI5 (Explain Like I’m 5)
- SHAP (SHapley Additive exPlanations)
These commonly used techniques can be configured using ML Pipelines in the C3 AI ML Studio, a low-code, lightweight interface for configuring multi-step machine learning models. Users can call a single and consistent API to interpret model predictions and do not need to worry either about specific interfaces or writing custom code. These techniques are interchangeable, increasing user flexibility to pick the best diagnosis tool.
TreeInterpreter is an interpretability framework focused on tree-based models such as random forest. This framework allows for the decomposition of decision trees into a series of decision paths from the root of the tree to the leaf. This makes interpretation of the model’s output straightforward, given the inherent interpretability of a decision tree. For example, we applied TreeInterpreter in a predictive maintenance application to detect boiler leakages in power plants. The underlying model in this AI system is a random forest classifier that predicts the likelihood of leakage. The features represent sound intensities of microphone sensors located at different points on the boiler. The spatial coordinates of the microphones are weighted with the corresponding feature contributions of each prediction to localize the potential leakage. Maintainers are preventing days of downtime by inspecting specific sections of the boiler to confirm and fix leakages more quickly.
ELI5 is another interpretability framework that supports widely used machine learning libraries such as scikit-learn, XGBoost, and LightGBM. We have leveraged ELI5 in financial services, helping financial institutions detect and prevent money laundering. Here we used a gradient-boosted classifier to learn suspicious patterns in transactions from historical cases. For regulatory and transparency reasons, our application needs to provide compliance investigators with prediction-level interpretability insights to help them make more informed decisions about client risk. Low-level features are usually neither useful nor actionable, so we constructed mapping to meaningful, high-level categories that aggregate individual feature contributions into money laundering typologies and scenarios such as shell accounts, trade finance, or structuring. This drove faster user adoption and supported regulatory approval.
Lastly, the SHAP framework is the most general approach. We used SHAP in a securities lending application to predict securities that would be shorted by the bank’s clients. Automatically and quickly estimating client demand increased inventory visibility for each stock, allowing the bank to broker more deals and increase revenue. The feature contributions helped build confidence in the machine learning model amongst trading desk personnel, who are now better equipped to issue shares of securities as loans to clients.
AI interpretability is a hot research area today and is evolving fast. At C3.ai, we contribute to global research and make use of the latest interpretability frameworks across our software stack to deliver value and trustworthy AI applications for our clients.
About the authors
Ryan Compton joined C3.ai as a senior data scientist in the spring of 2020. He has worked on projects ranging from financial securities lending to assembly yield optimization. He earned his PhD in computer science from the University of California, Santa Cruz.
Romain Juban is a principal data scientist at C3.ai and has worked on multiple projects across several industries (utilities, oil and gas, aerospace and defense, banking, and manufacturing) since 2014. He earned his bachelor’s in applied mathematics from Ecole Polytechnique in France and his master’s in civil and environmental engineering from Stanford University.
Sina Pakazad is a lead data scientist at C3.ai. Since 2017, he has worked with different problems involving predictive maintenance, anomaly detection, optimization, and decision making under uncertainty within a variety of industries, including financial services, oil and gas, process industry and manufacturing. Before C3.ai, he was an experienced researcher at Ericsson Research in Stockholm. He received his master’s in systems, control and mechatronics from Chalmers University in Gothenburg, Sweden, and his PhD in automatic control from Linköping University in Sweden.